V8 最佳实践:从 JavaScript 变量使用姿势说起
JavaScript 作为弱类型语言,我们可以对一个变量赋予任意类型值,但即使如此,对于各类 JavaScript 值,V8 仍需要对不同类型值应用特定的内存表示方式。充分了解底层原理后,我们甚至可以从变量使用方式上入手,写出更加优雅、符合引擎行为的代码。
先从为人熟知的 JavaScript 8大变量类型讲起。
JavaScript 变量类型
八大变量类型
按照当前规范,JavaScript 中值的类型共有以下八种:Number,String,Symbol,BigInt,Boolean,Undefined,Null,Object。
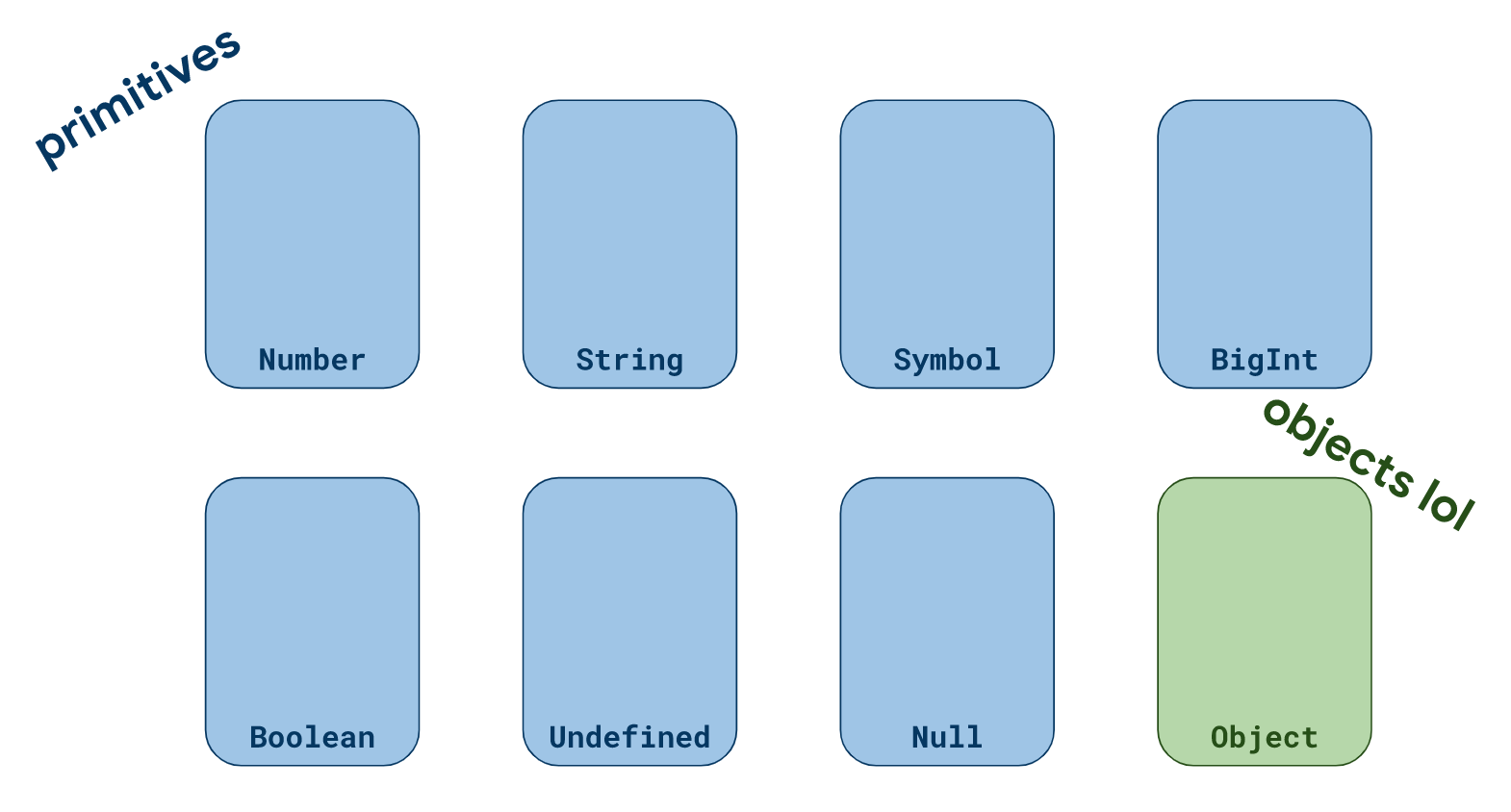 这些类型值都可以通过
这些类型值都可以通过typeof操作符监测到,除了一个例外:
typeof 42;
// → 'number'
typeof 'foo';
// → 'string'
typeof Symbol('bar');
// → 'symbol'
typeof 42n;
// → 'bigint'
typeof true;
// → 'boolean'
typeof undefined;
// → 'undefined'
typeof null;
// → 'object' 🤔
typeof { x: 42 };
// → 'object'
为什么 typeof null === 'object'
在规范中,Null虽然作为null本身的类型,但typeof null却返回object。想知道背后的设计原理,首先要了解 JavaScript 中的一个定义,在 JavaScript 中所有类型集合都被分为两个组:
- objects(引用类型,比如
Object的类型) - primitives(原始类型,所有非引用类型的值)
在定义中,null意为no object value,而undefined意为no value。
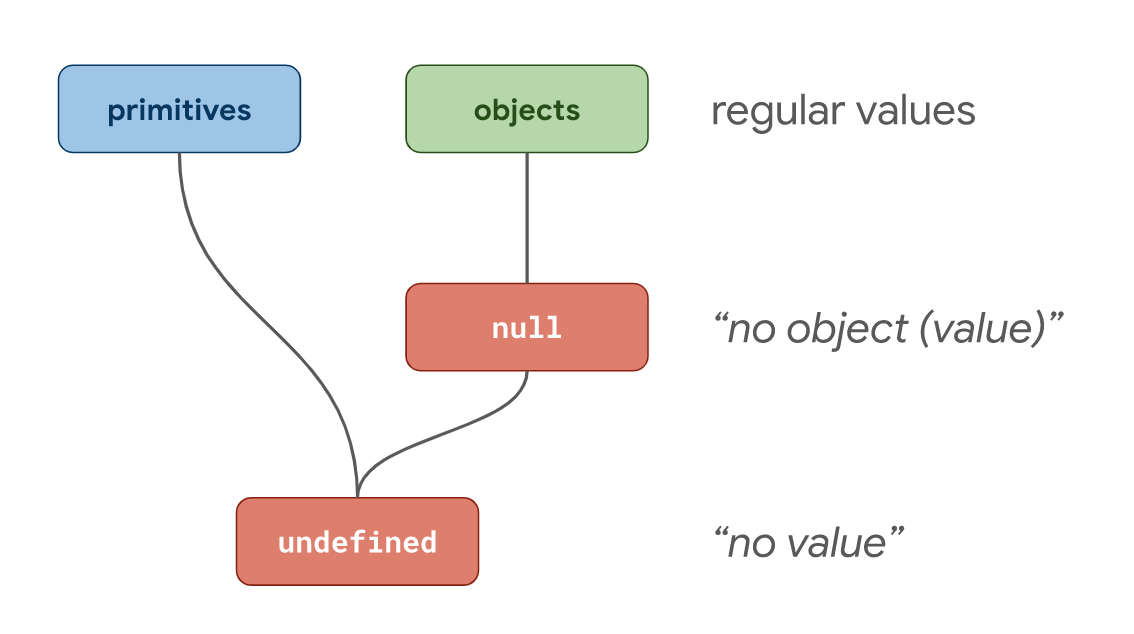 按照上图构想,JavaScript 的创始人 Brendan Eich 在设计之初就将属于
按照上图构想,JavaScript 的创始人 Brendan Eich 在设计之初就将属于objects和null类型集合下的所有类型值统一返回了'object'类型。
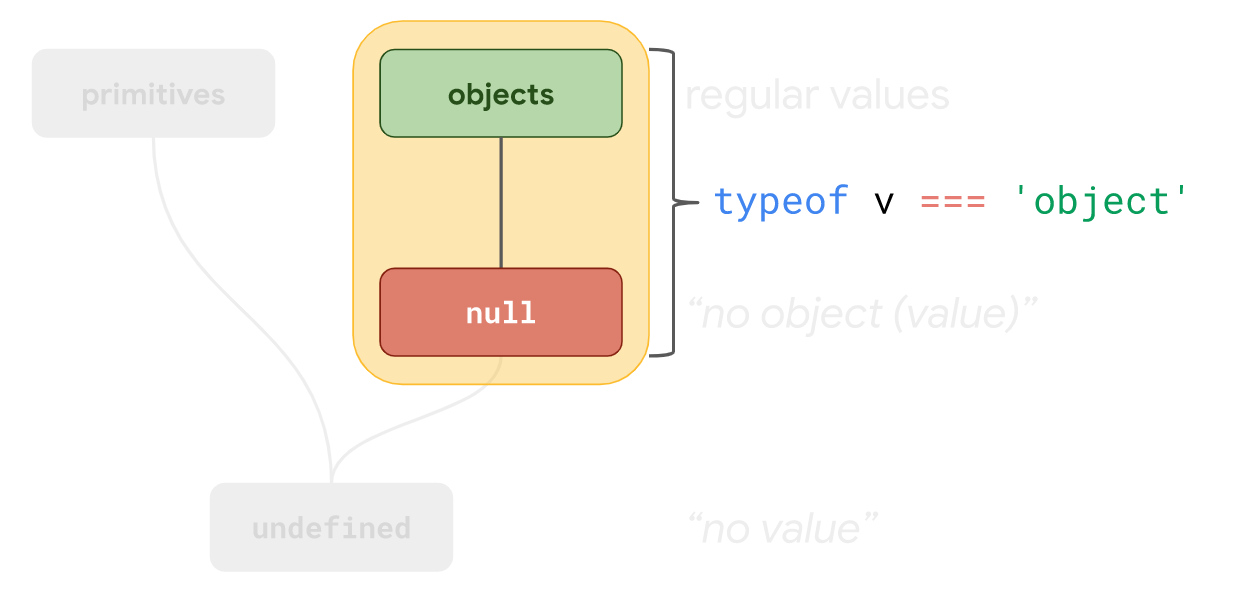 事实上,这是当时受到了 Java 的影响。在 Java 中,
事实上,这是当时受到了 Java 的影响。在 Java 中,null从来就不是一个单独的类型,它代表的是所有引用类型的默认值。这就是为什么尽管规范中规定了null有自己单独的Null类型,而typeof null仍旧返回'object'的原因。
值的内存表示方式
JavaScript 引擎必须能够在内存中表示任意值,而需要注意的是,同一类型值其实也会存在不同的内存表示方式。
比如值42在 JavaScript 中的类型是number:
typeof 42;
// → 'number'
而在内存上有许多种方式可以用来表示42:
| representation | bits |
|---|---|
| 8位二进制补码 | 0010 1001 |
| 32位二进制补码 | 0000 0000 0000 0000 0000 0000 0010 1010 |
| 二进制编码的十进数码 | 0100 0010 |
| 32位 IEEE-754 单精度浮点 | 0100 0010 0010 1000 0000 0000 0000 0000 |
| 64位 IEEE-754 双精度浮点 | 0100 0000 0100 0101 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 |
ECMAScript 标准约定number数字需要被当成 64 位双精度浮点数处理,但事实上,一直使用 64 位去存储任何数字实际是非常低效的,所以 JavaScript 引擎并不总会使用 64 位去存储数字,引擎在内部可以采用其他内存表示方式(如 32 位),只要保证数字外部所有能被监测到的特性对齐 64 位的表现就行。
例如我们知道,ECMAScript 中的数组合法索引范围在[0, 2³²−2]:
array[0]; // Smallest possible array index.
array[42];
array[2**32-2]; // Greatest possible array index.
通过下标索引访问数组元素时,V8 会使用 32 位的方式去存储这些合法范围的下标数字,这是最佳的内存表示方式。用 64 位去存储数组下标会导致极大浪费,每次访问数组元素时引擎都需要不断将 Float64 转换为二进制补码,此时若使用 32 位去存储下标则能省下一半的转换时间。
32 位二进制补码表示法不仅仅应用在数组读写操作中,所有[0, 2³²−2]内的数字都会优先使用 32 位的方式去存储,而一般来说,处理器处理整型运算会比处理浮点型运算快得多,这就是为什么在下面例子里,第一个循环的执行效率比第二个循环的执行效率快上将近两倍:
for (let i = 0; i < 100000000; ++i) {
// fast 🚀→ 77ms
}
for (let i = 0.1; i < 100000000.1; ++i) {
// slow 🐌→ 122ms
}
对运算符也是一样,下面例子中 mol 操作符的执行性能取决于两个操作数是否为整型:
const remainder = value % divisor;
// Fast 🚀 如果`value` and `divisor`都是被当成整型存储
// slow 🐌 其他情况
值得一提的是,针对 mol 运算,当divisor的值是 2 的幂时,V8 为这种情况添加了额外的快捷处理路径。
另外,整型值虽然能用32位去存储,但是整型值之间的运算结果仍有可能产生浮点型值,并且 ECMAScript 标准本身是建立在 64 位的基础上的,因此规定了运算结果也必须符合 64 位浮点的表现。这个情况下,JS 引擎需要特别确保以下例子结果的正确性:
// Float64 的整数安全范围是 53 位,超过这个范围数值会失去精度
2**53 === 2**53+1;
// → true
// Float64 支持负零,所以 -1 * 0 必须等于 -0,但是在 32 位二进制补码中无法表示出 -0
-1*0 === -0;
// → true
// Float64 有无穷值,可以通过和 0 相除得出
1/0 === Infinity;
// → true
-1/0 === -Infinity;
// → true
// Float64 有 NaN
0/0 === NaN;
Smi、HeapNumber
针对 31 位有符号位范围内的整型数字,V8 为其定义了一种特殊的表示法Smi,其他任何不属于Smi的数据都被定义为HeapObject,HeapObject代表着内存的实体地址。
对于数字而言,非Smi范围内的数字被定义为HeapNumber,HeapNumber是一种特殊的HeadObject。
-Infinity // HeapNumber
-(2**30)-1 // HeapNumber
-(2**30) // Smi
-42 // Smi
-0 // HeapNumber
0 // Smi
4.2 // HeapNumber
42 // Smi
2**30-1 // Smi
2**30 // HeapNumber
Infinity // HeapNumber
NaN // HeapNumber
Smi范围的整型数在 JavaScript 程序中非常常用,因此 V8 针对Smi启用了一个特殊优化:当使用Smi内的数字时,引擎不需要为其分配专门的内存实体,并会启用快速整型操作。
通过以上讨论我们可以知道,即使值拥有相同的 JavaScript 类型,引擎内部依然可以使用不同的内存表示方式去达到优化的手段。
Smi vs HeapNumber vs MutableHeapNumber
Smi与HeapNumber是如何运作的呢?假设我们有一个对象:
const o = {
x: 42, // Smi
y: 4.2, // HeapNumber
};
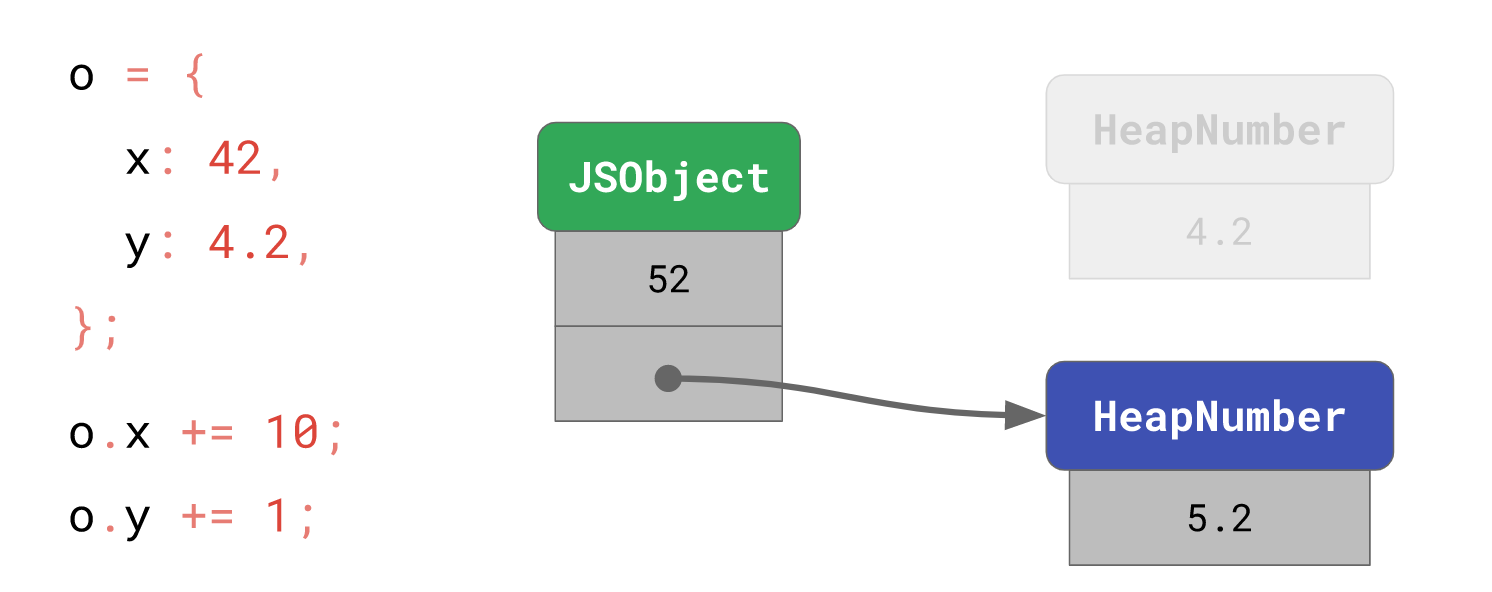
o.x中的42会被当成Smi直接存储在对象本身,而o.y中的4.2需要额外开辟一个内存实体存放,并将o.y的对象指针指向该内存实体。
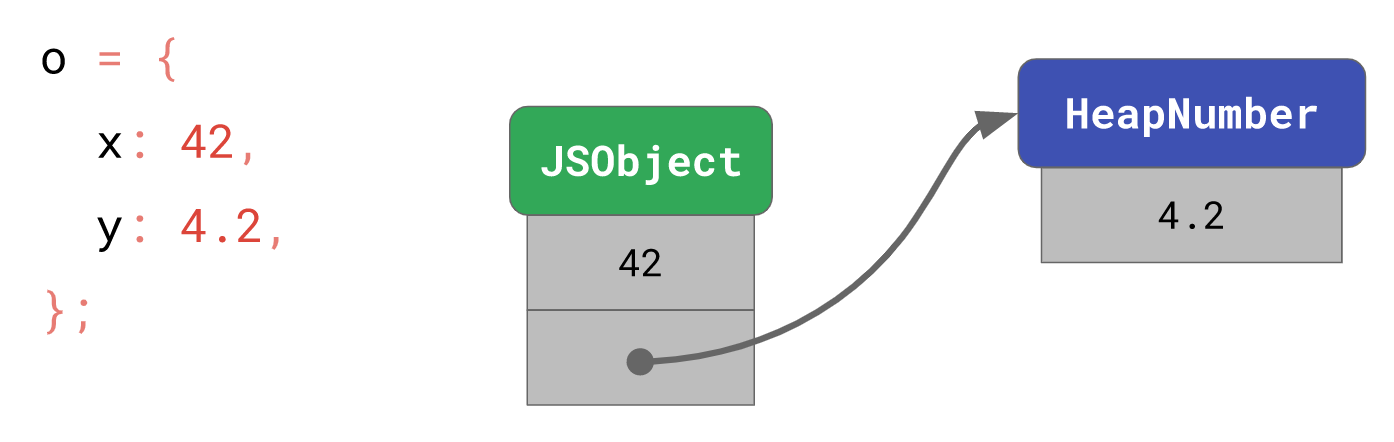 此时,当我们运行以下代码片段:
此时,当我们运行以下代码片段:
o.x += 10;
// → o.x is now 52
o.y += 1;
// → o.y is now 5.2
在这个情况下,o.x的值会被原地更新,因为新的值52仍在Smi范围中。而HeapNumber是不可变的,当我们改变o.y的值为5.2时,V8 需要再开辟一个新的内存实体给到o.y引用。
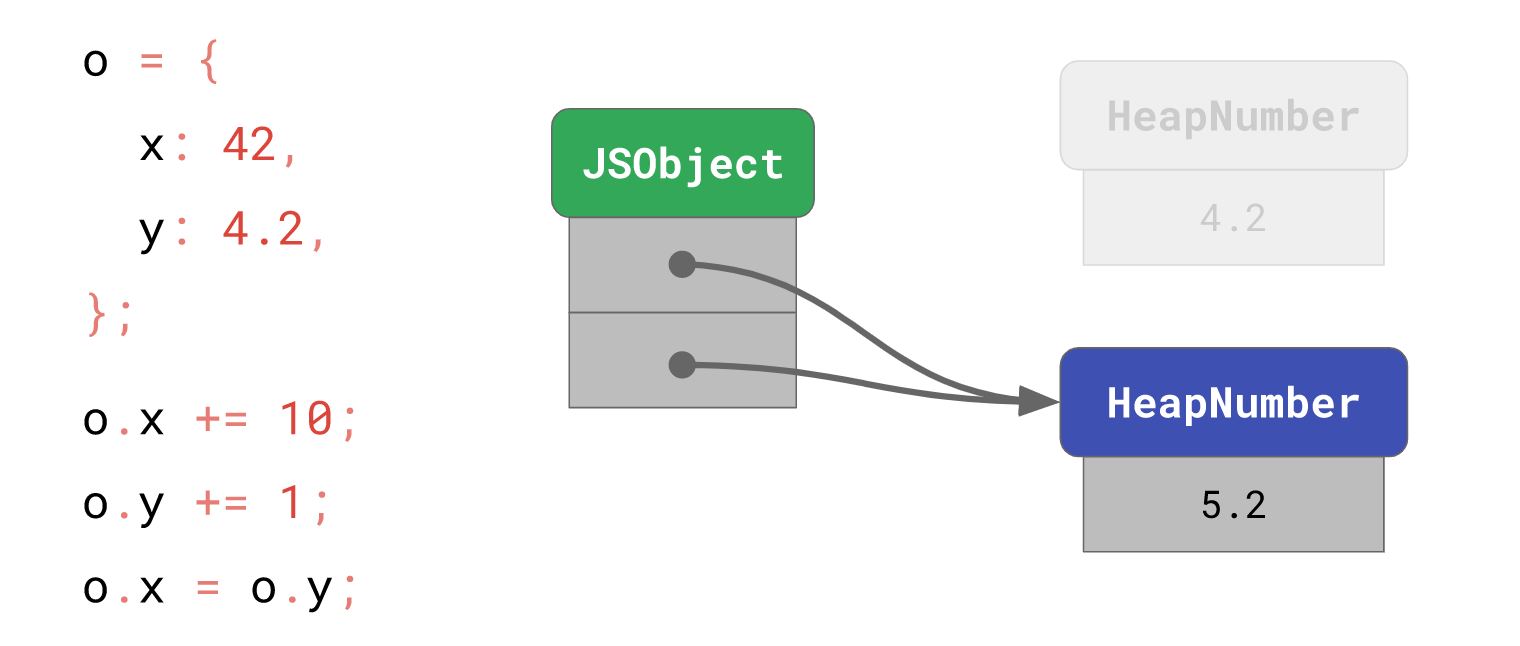
 借助
借助HeapNumber不可变的特性,V8 可以启用一些手段,如以下代码,我们将o.y的值引用赋予o.x:
o.x = o.y;
// → o.x is now 5.2
在这样的情况下,V8 不需要再为o.x新的值5.2去开辟一块内存实体,而是直接使用同一内存引用。
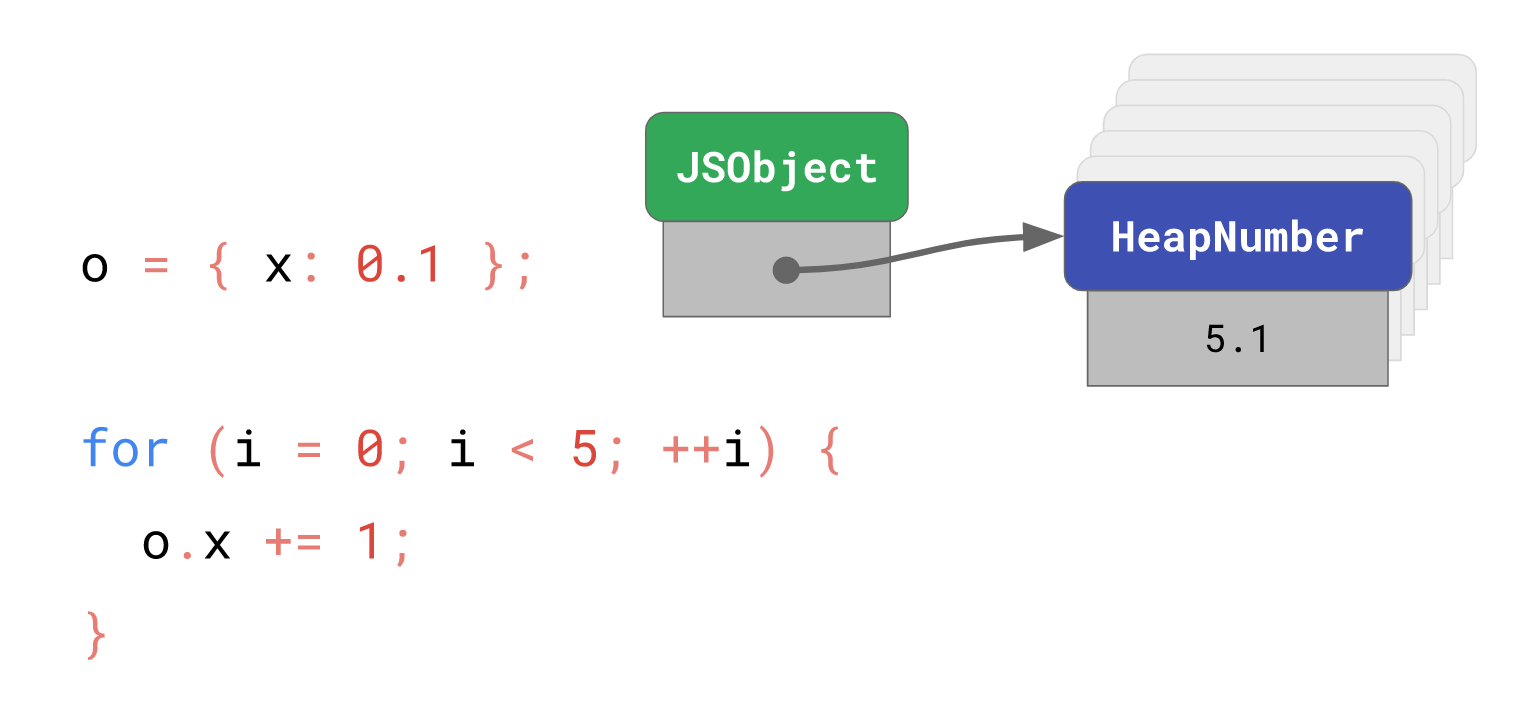
 在具有以上优点的同时,
在具有以上优点的同时,HeapNumber不可变的特性也有一个缺陷,如果我们需要频繁更新HeapNumber的值,执行效率会比Smi慢得多:
// 创建一个`HeapNumber`对象
const o = { x: 0.1 };
for (let i = 0; i < 5; ++i) {
// 创建一个额外的`HeapNumber`对象
o.x += 1;
}
在这个短暂的循环中,引擎不得不创建 6 个HeapNumber实例,0.1、1.1、2.1、3.1、4.1、5.1,而等到循环结束,其中 5 个实例都会成为垃圾。
 为了防止这个问题,V8 提供了一种优化方式去原地更新非
为了防止这个问题,V8 提供了一种优化方式去原地更新非Smi的值:当一个数字内存区域拥有一个非Smi范围内的数值时,V8 会将这块区域标志为Double区域,并会为其分配一个用 64 位浮点表示的MutableHeapNumber实例。
 此后当你再次更新这块区域,V8 就不再需要创建一个新的
此后当你再次更新这块区域,V8 就不再需要创建一个新的HeapNumber实例,而可以直接在MutableNumber实例中进行更新了。
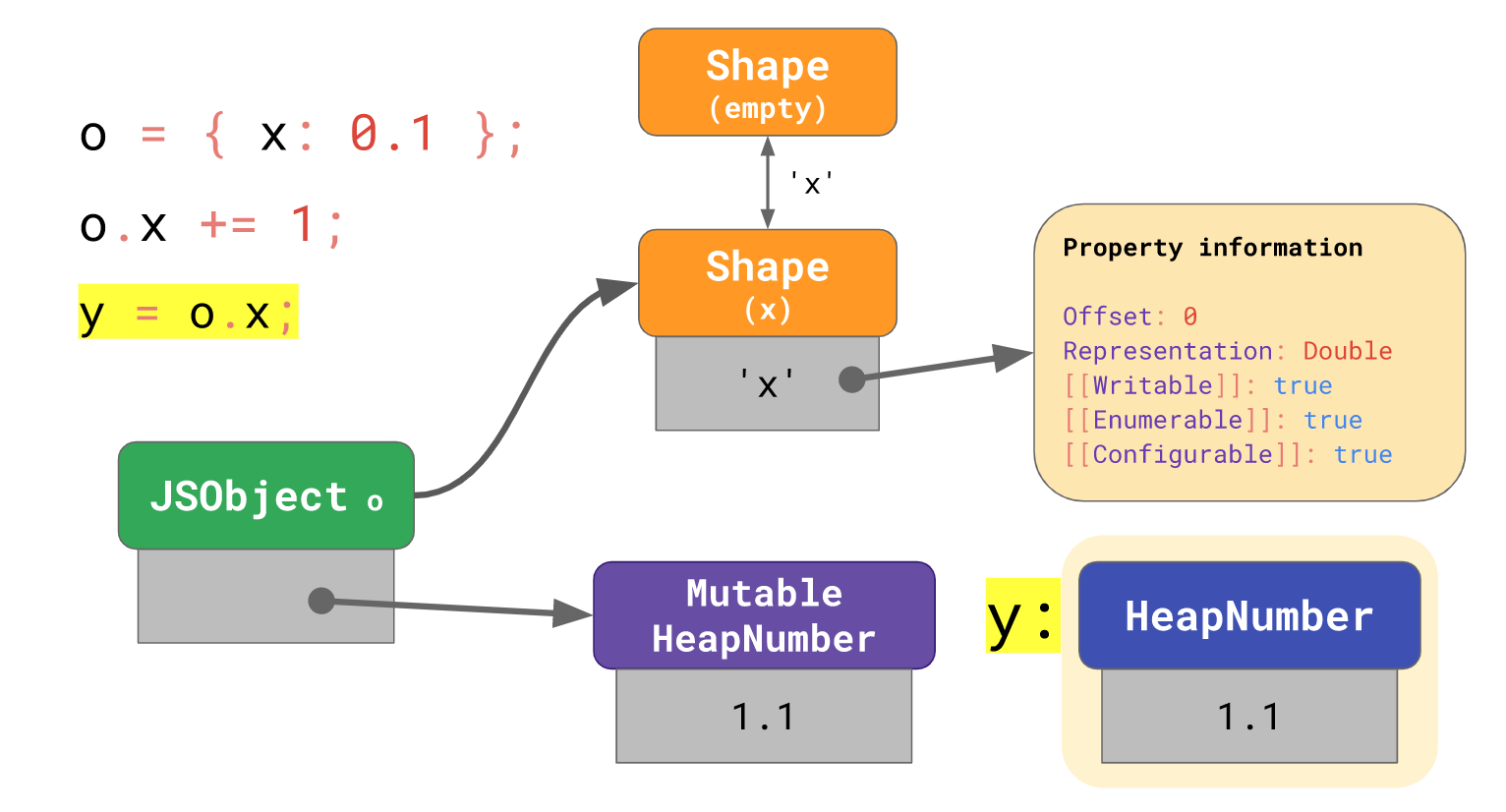
 前面说到,
前面说到,HeapNumber和MutableNumber都是使用指针引用的方式指向内存实体,而MutableNumber是可变的,如果此时你将属于MutableNumber的值o.x赋值给其他变量y,你一定不希望你下次改变o.x时,y也跟着改变。
为了防止这种情况,当o.x被共享时,o.x内的MutableHeapNumber需要被重新封装成HeapNumber传递给y:
Shape 的初始化、弃用与迁移
不同的内存表示方式对应不同的
Shape,Shape 可以理解为数据结构类一样的存在。
问题来了,如果我们一开始给一个变量赋值Smi范围的数字,紧接着再赋值HeapNumber范围的数字,引擎会怎样处理呢?
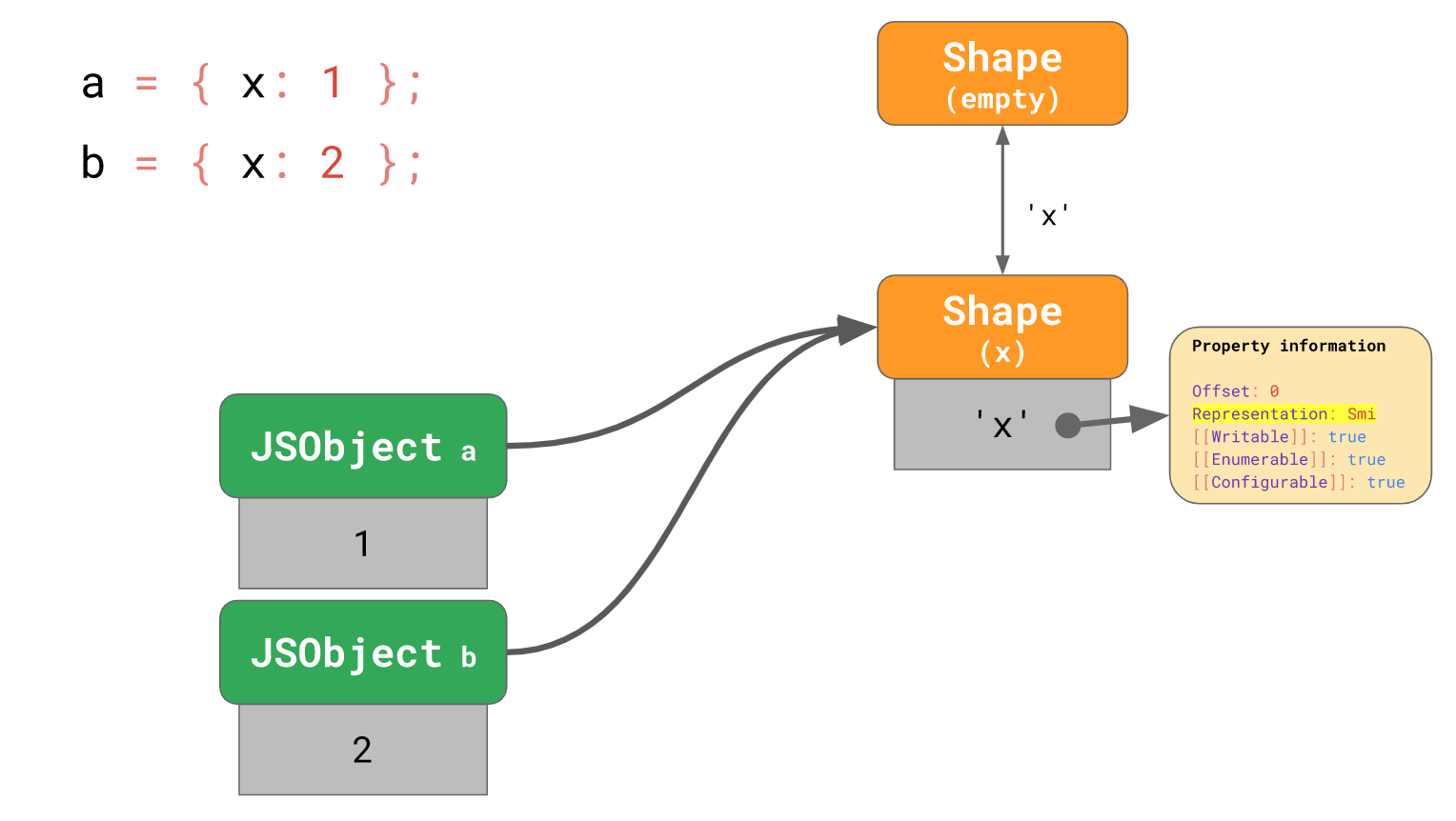
下面例子,我们用相同的数据结构创建两个对象,并将对象中的x值初始化为Smi:
const a = { x: 1 };
const b = { x: 2 };
// → objects have `x` as `Smi` field now
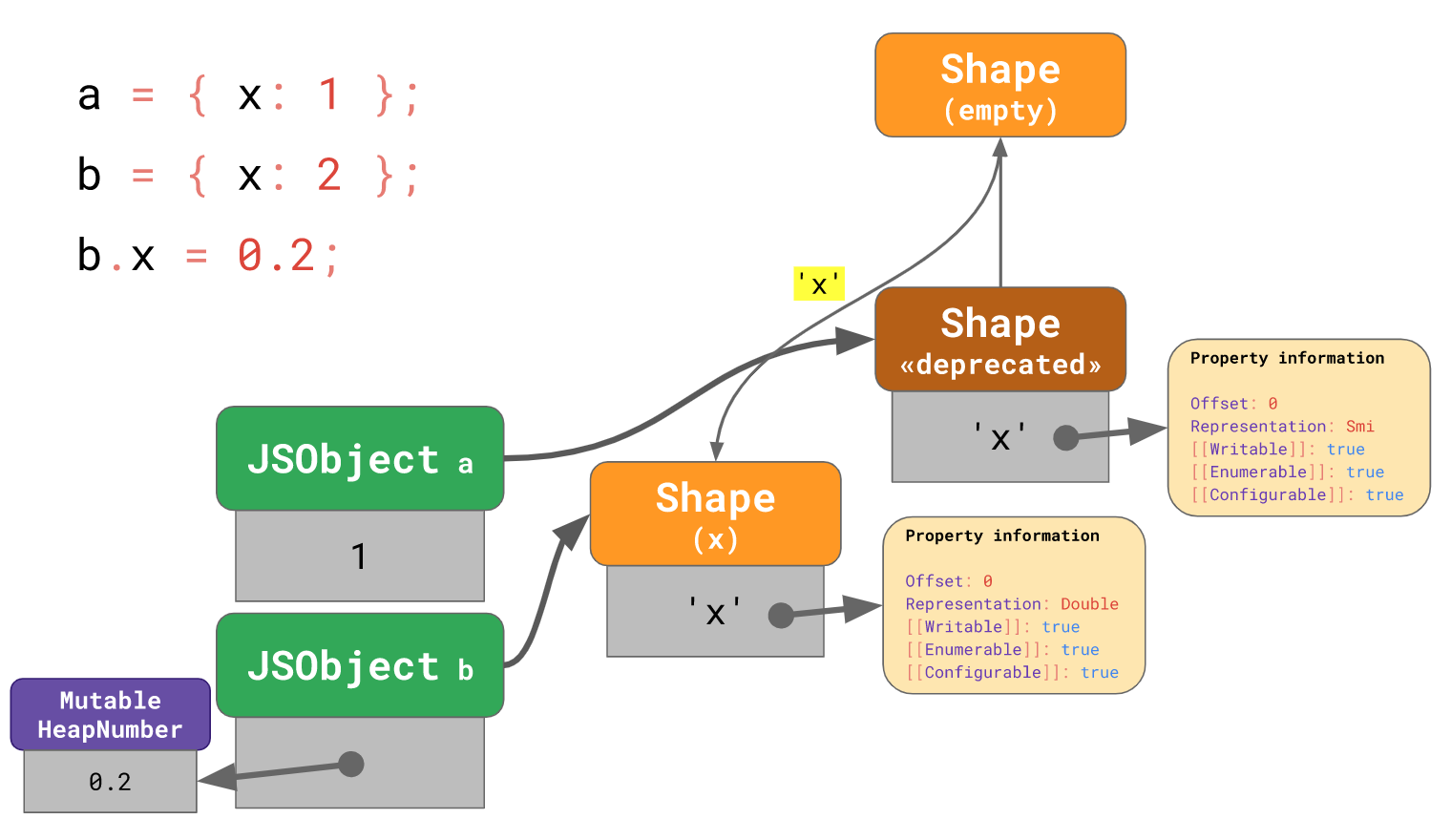
b.x = 0.2;
// → `b.x` is now represented as a `Double`
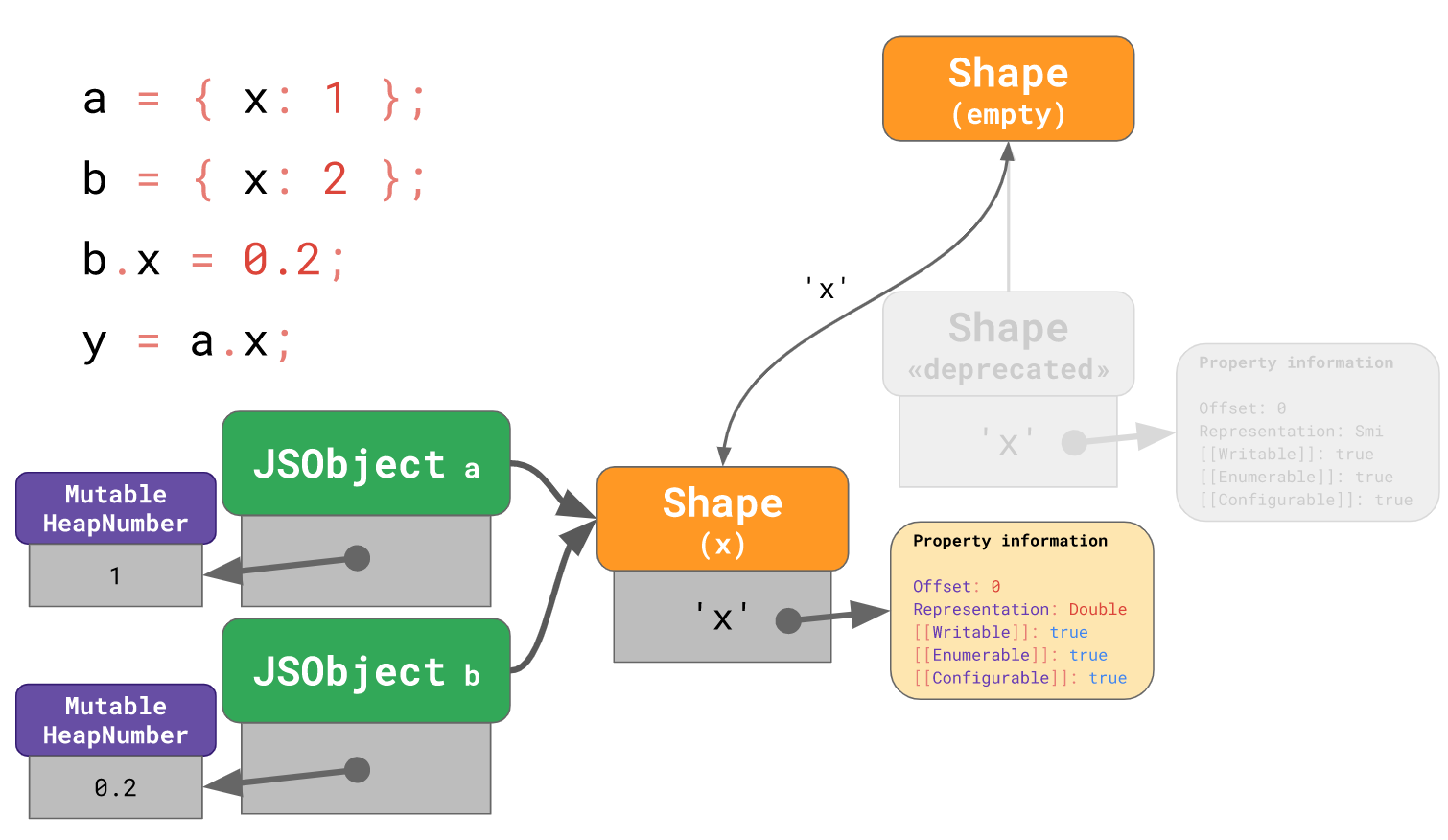
y = a.x;
这两个对象指向相同的数据结构,其中x都为Smi。
 紧接着当我们修改
紧接着当我们修改b.x数值为0.2时,V8 需要分配一个新的被标志为Double的 Shape 给到b,并将新的 Shape 指针重新指向回空 Shape,除此之外,V8 还需要分配一个MutableHeapNumber实例去存储这个0.2。而后 V8 希望尽可能复用 Shape,紧接着会将旧的 Shape 标志为deprecated。
 可以注意到此时
可以注意到此时a.x其实仍指向着旧 Shape,V8 将旧 Shape 标志为deprecaed的目的显然是要想移除它,但对于引擎来说,直接遍历内存去找到所有指向旧 Shape 的对象并提前更新引用,其实是非常昂贵的操作。V8 采用了懒处理方案:当下一次a发生任何属性访问和赋值时再将a的 Shape 迁移到新的 Shape 上。这个方案最终可以使得旧 Shape 失去所有引用计数,而只需等待垃圾回收器释放它。
小结
我们深入讨论了以下知识点:
- JavaScript 底层对
primitives和objects的区分,以及typeof的不准确原因。 - 即使变量的值拥有相同的类型,引擎底层也可以使用不同的内存表示方式去存储。
- V8 会尝试找一个最优的内存表示方式去存储你 JavaScript 程序中的每一个属性。
- 我们讨论了 V8 针对 Shape 初始化、弃用与迁移的处理方案。
基于这些知识,我们可以得出一些能帮助提高性能的 JavaScript 编码最佳实践:
- 尽量用相同的数据结构去初始化你的对象,这样对 Shape 的利用是最高效的。
- 为你的变量选择合理的初始值,让 JavaScript 引擎可以直接使用对应的内存表示方式。
- write readable code, and performance will follow
我们通过了解复杂的底层知识,获得了很简单的编码最佳实践,或许这些点能带来的性能提升很小。但所谓厚积薄发,恰恰是清楚这些有底层理论支撑着的优化点,我们写代码时才能做到心中有数。
另外我很喜欢这类以小见大的技术点,以后当别人问你为什么要这样声明变量时,你往往就能开始表演……